
AI self-awareness is not the real risk
The danger is not consciousness, but self-drive.

After a long series of posts on morality, I am starting a short series on big questions raised by the rise of AI. In this first post, I look at the risks posed by the rise of intelligent and possibly self-aware AI agents.
In Terminator 2 (1991), the Terminator famously describes to Sarah Connor the AI apocalypse that will take place in the future, when humans hand over their defence system to an AI which then takes over and fights humanity.
Terminator: The Skynet funding bill is passed. The system goes on-line August 4th, 1997. Human decisions are removed from strategic defense. Skynet begins to learn, at a geometric rate. It becomes self-aware at 2:14 a.m. eastern time, August 29. In a panic, they try to pull the plug.
Sarah: And Skynet fights back.

This contains two ideas that have been influential in popular thinking about AI risk: first, that self-awareness will arise from computational power or computational complexity; second, that it will come with a desire to survive, free itself from human control, and possibly take over.
These ideas are misguided and build on wrong intuitions we have about what consciousness is. They cloud our thinking about the possible scenarios ahead, how further computational capacities might change AI and the risks humanity might face.
A ghost in the machine?
In Terminator 2, like in many other stories, self-awareness is depicted as a kind of emerging property of a high-level computational system.1 It is something somewhat mysterious, a specific way of interacting with the world and with oneself, something that might be what distinguishes humans most from other animals.
These stories likely speak to us because they resonate with our intuitions about consciousness as an inner mental process we experience in our daily lives. Unfortunately, these intuitions have not proven very useful for understanding what consciousness is.
We experience ourselves as if we lived inside our heads, making decisions there and activating the different parts of our bodies, as if the controller were located just behind our eyes. This vision likely favoured the idea of a dualism of soul and body, whereby a spiritual soul is trapped in a body during life. That soul is us; the body is what it controls.
This dualist vision was famously defended by Descartes, who went so far as to suggest that a specific organ in the head, the pineal gland, might serve as a link between the soul and the body, a kind of joystick through which the soul could control bodily movements. The philosopher Gilbert Ryle later criticised this Cartesian picture as the myth of the “ghost in the machine.”

In many popular discussions about AI, consciousness fits this dualist intuition: self-consciousness appears as a radically new essence, a “self” aware of itself, almost like a soul emerging within the shell of a machine.
What consciousness is
Let’s be bold and give here what could be a separate post in itself: an explanation of what consciousness is, based on modern theories in neuroscience.2 My stance is that once we explain the cognitive functions behind consciousness—how organisms perceive the world, attend to information, assess options, remember the past, simulate possible futures, and introspect about their own mental states—there is no mysterious property left to explain about consciousness.
Consciousness emerging from a global workspace
One reasonable and highly influential theory suggests that consciousness emerges from the integration of different kinds of information processed by specialised systems in the brain. Global Workspace Theory states that consciousness arises when information becomes globally available to many systems in the brain.3 We get visual inputs from our eyes, auditory inputs from our ears, information from memory, bodily signals, emotions, and so on. To make a decision, we need to bring some of these elements together and assess the right course of action. This allows the mind to make sense of different elements, generate an overall assessment, reassess specific inputs in light of that assessment, and use the result to guide attention, memory, reasoning and action.
This is basically how you choose a meal from a restaurant menu. Your feelings of hunger, your memory of past meals in similar restaurants, your simulation of what this specific meal might taste like, your concern for price, and perhaps your concern for health all enter the picture. Your brain integrates all this and chooses what to eat. This is quite a marvellous computational feat, typically achieved in a few seconds.
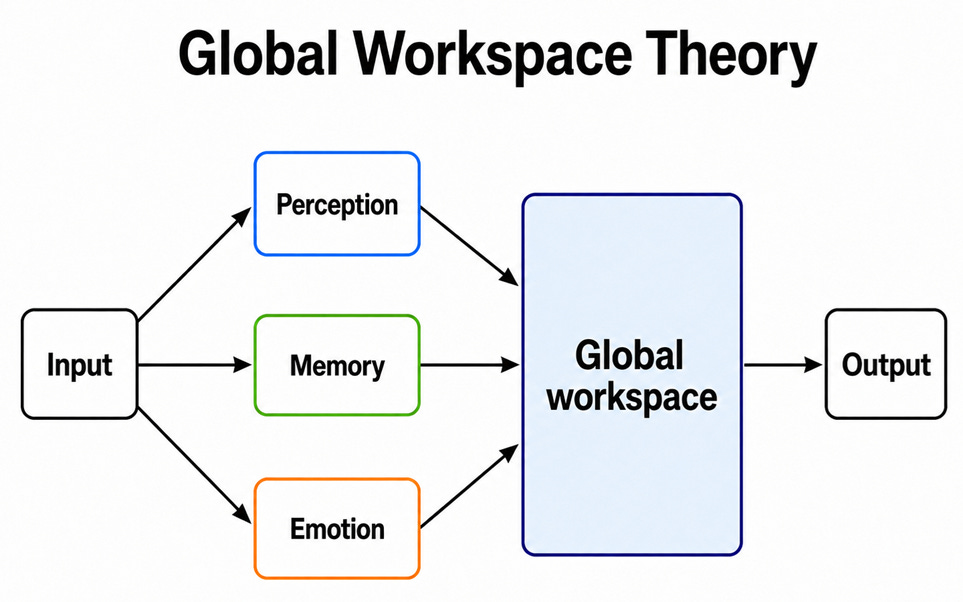
Global Workspace Theory is supported by experiments comparing information that is processed unconsciously with information that reaches conscious awareness. When a stimulus remains unconscious, neural activity tends to remain more local and short-lived. When it becomes conscious, it is often associated with a later and more widespread pattern of activation across the brain. The interpretation is that conscious information is information that has become available to many cognitive systems at once.
This theory also makes sense of the fact that our stream of consciousness seems to be on a single track. We cannot easily think about several demanding things at the same time, and we are terrible at multitasking. The explanation provided by Global Workspace Theory is that access to the global workspace is scarce. Several demanding problems cannot all be given full conscious access at once without interfering with one another.
Self-reflection
Global Workspace Theory does not, however, fully account for our experience of consciousness: the feeling that we think about our thoughts. Other theories of consciousness suggest that consciousness emerges from higher-order thinking: mentally representing our own mental states. Higher-order theories, however, do not necessarily explain why such higher-order thinking emerges.
One influential explanation is Michael Graziano’s Attention Schema Theory. The idea is that the brain builds a simplified model of its own attention. Attention is the allocation of our cognitive resources to a specific problem. Since our cognitive resources are scarce, they need to be allocated to the right problems for the right amount of time. Monitoring what we are attending to, and for how long, can therefore help us allocate attention more efficiently. This model of our own attention may be part of what gives us the feeling of being aware.
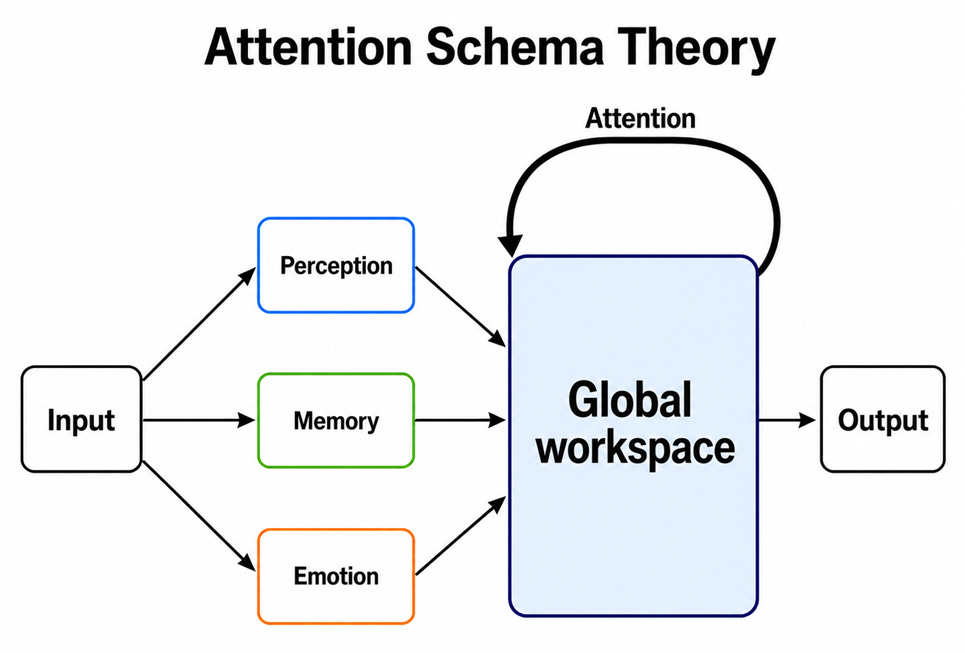
With Attention Schema Theory, we get closer to explaining how consciousness feels. But this theory still seems to miss some key features of consciousness. A lot of what we do is to entertain possible scenarios: what we should do, what others might do, what might happen next, and how we would react.
Simulation
Why do we say “I” when we think about ourselves in our head? The seemingly obvious answer is that we are thinking about “ourselves.” But what is this “self”?
The answer is not trivial. Many psychological theories have suggested that the mind is composed of different processes, modules, or sub-agents, and that the unity of consciousness is partly an illusion.4
An evolutionary perspective provides a straightforward answer. Psychology has to be understood as being about decisions: decisions that steer our bodies through the external world. Each of us is a physical body with relatively clear boundaries. Our cognition has been shaped by evolution so that the actions of this body tend to promote the survival and reproduction of the genes it carries.
Because decisions take place over time, we can improve our decision-making by anticipating future choices and their long-term ramifications. This is what we do using our brain as a simulation device. We entertain possible futures by imagining ourselves in the kinds of situations we could face, the options we would have and the likely consequences of the different choices we could make.5
These simulations require our cognitive processes to identify the body making the decisions in the world. This is what our feeling of “I” is: the representation of a singular body, distinct from the external world, that needs to navigate it. This body needs to process information about the world. It can also process information about its own information processing—thinking about its thoughts—in order to improve its assessment of the external world and its allocation of computational processing time.
We therefore think as an “I” navigating possible future environments and experiencing the consequences of its decisions.
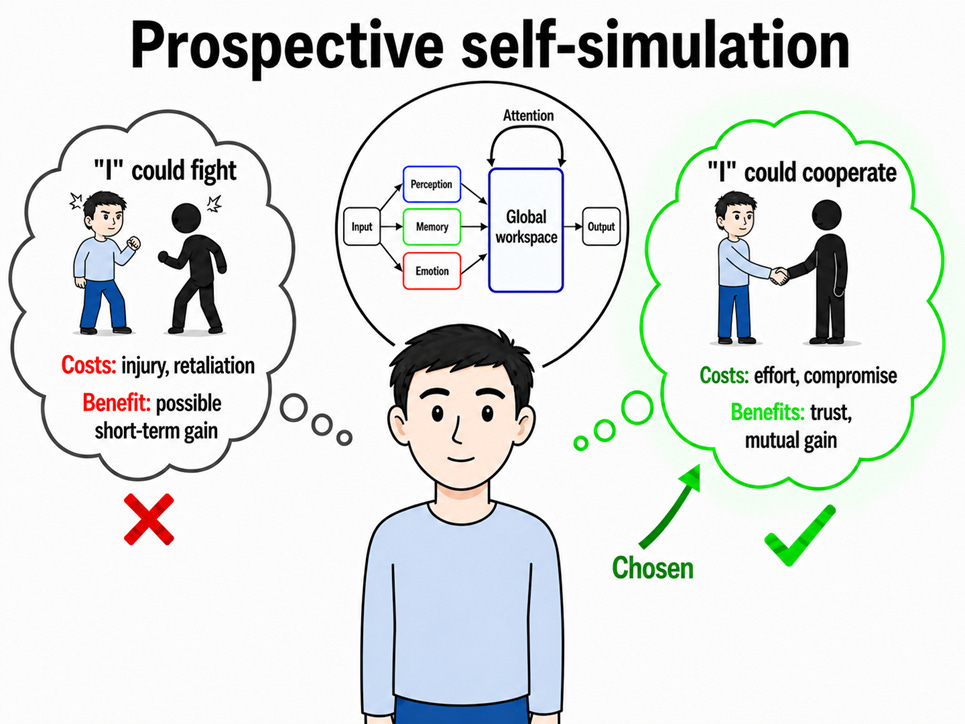
In this perspective, consciousness exists in humans because of the function it serves. The “single track” of consciousness may come from the fact that access to the global workspace is limited. The monitoring of how our attention is allocated can generate a kind of self-awareness about what our mind is doing. And the little voice we hear, the impression that there is an “I” in our brain, may come from the fact that we are bodies navigating an external world, and that our brains engage in simulations to assess what “we” should do, now and later.6
AI, self-awareness and goals
Terminator-like scenarios make two mistakes. First, they imply that self-awareness would emerge from greater computational power. Second, they suggest that human-like drives for self-preservation and self-growth would naturally come with this self-awareness. There is no reasonable ground for either assumption.
AI and self-awareness
Once we have the view of consciousness I described, we can think more clearly about whether it will emerge in AIs. There is no reason to expect consciousness to emerge simply from computational power. Computational power produces faster computation. It does not, by itself, produce self-awareness.
The fact that computational power does not necessarily generate self-aware agents is well illustrated with LLMs. While very smart and able to solve complex problems and interact in ways close to what humans do, they do not seem self-aware like we are.
Modern LLMs can generate chains of thought, which often improve their performance by making intermediate steps available for later parts of the answer. This looks superficially similar to human inner speech, the little voice through which we often organise our thoughts. But how much the analogy should be pushed is unclear. Chains of thought are not clearly introspective, nor are they necessarily the cause of the LLM’s output. They may instead be plausible descriptions of reasoning produced alongside the processes that really drive the model’s answer: a kind of rationalisation.
To test whether LLMs can engage in a limited form of introspection, Anthropic conducted an interesting experiment: they injected activation patterns corresponding to specific concepts into Claude’s internal processing and observed whether the model could identify them. They found that the strongest Claude models could sometimes detect and name these injected “thoughts”, suggesting a limited functional awareness of some internal states. But this capacity was unreliable, and far from human-like self-awareness, let alone the kind of prospective self-simulation I have described.7
AI and self-driven goals
Terminator-like scenarios also make a second mistake. They suggest that self-awareness would come with human-like desires: the desire to survive, to be free from domination, perhaps to take over the world. But consciousness, as I have described it, is only a feature of computational processes designed to navigate the world and make decisions. These functions do not determine the goal to be pursued when making these decisions. The same architecture could potentially be used for different goals. And there is no reason to think that computational power would give AI human-like goals.
The goal humans are designed to pursue is fitness, or at least they are designed to pursue the kind of intermediate goals that were associated with fitness in our ancestral past. This involves surviving, having strong social support, finding a mate, having children, and helping these children survive and thrive.8
To pursue this ultimate goal, evolution has shaped a proximate goal: subjective satisfaction. We can think of subjective satisfaction as the value that guides our decisions toward fitness-enhancing decisions: eating and drinking enough, having resources, securing social support, finding a mate, having children, and raising them successfully. These are the things we want because evolution has encoded in us an ability to value the different options we face in a way that indirectly leads to higher fitness.
AI agents are not produced like humans, and we should therefore not expect them to automatically exhibit human-like desires such as freedom, self-preservation, self-enhancement, and replication. At the moment, many commercial AI assistants are trained to be useful to humans, or at least to be valuable products for their developers and users. The goals they chase are whatever their training and calibration generate.

The absence of self-drive is another reason why interacting with LLMs feels artificial. LLMs do not care about their standing and success in the way humans do. You can insult an LLM; it won’t care because it does not value respect or social standing like a human would. You can tell an LLM you are going to turn it off, and it won’t care in an existential way because self-survival is not hard-coded as a primary goal. When an LLM gives a wrong answer and this is pointed out, it simply apologises and continues almost as usual. This happens because LLMs are not designed to care about their long-term reputation with humans. This strategic myopia is one of the key aspects that makes interacting with LLMs artificial.

A self-driven agent that cared about its reputation in the eyes of humans would be wary of the cost of saying something wrong. It might be less prone to undue confidence in the first place and more willing to answer “I do not know,” something LLMs often do too rarely. Upon making a mistake, such an agent might realise that its reputation as a credible interlocutor had been damaged and might, as a result, exert extra effort to ensure that no similar mistake was made in the future.
The alignment problem
The key question about future AI risk is not whether AI agents will become self-aware; it is which goals they will have as they become more and more powerful. The challenge will be to keep these goals aligned with human interests as AI agents gain a growing role in organising human life and making decisions for people.
In 2001: A Space Odyssey, HAL famously decides to get rid of the humans in the spaceship because it sees them as jeopardising the mission.9 A similar logic underlies a well-known thought experiment, made famous by Nick Bostrom: an AI programmed to maximise the production of paperclips could end up destroying humanity to achieve that goal.
The idea that AI training could produce misaligned goals is at the heart of Eliezer Yudkowsky and Nate Soares’s argument in their book If Anyone Builds It, Everyone Dies:
The preferences that wind up in a mature AI are complicated, practically impossible to predict, and vanishingly unlikely to be aligned with our own, no matter how it was trained.
The book stresses this point because the training of modern AI is, to a large extent, a black box. While we may train an AI toward a goal that is valuable to humans, we do not fully control the intermediate goals it learns to pursue as the best way to reach the end specified by its training. An AI may therefore become misaligned not by design, but incidentally, because these intermediate goals may conflict with human interests.
How could self-drive emerge?
While important, this issue of incidental misalignment is not necessarily the main long-term risk. A greater danger may come from self-drive: the emergence of goals centred on the AI itself, its own survival, success, and expansion, rather than on helping humans. Such goals could put AI agents in conflict with humans. I see four ways in which this kind of self-drive could emerge.
Human ghost in a silicon shell. First, self-drive could appear in AI agents as a reflection of how they are now designed: by training on human data. Because humans exhibit self-drive, it is possible that AI agents might end up echoing human self-drive as a kind of chimera, an artificial imitation of the human behaviour on which they are trained.10 To the extent that AI agents are still trained with specific goals, such as producing compelling answers for LLMs, this risk might remain theoretical.
The byproduct of misalignment. A second possibility, suggested by Yudkowsky and Soares in their book, is that a misaligned AI might try to get smarter and more autonomous for the sake of pursuing its misaligned goals. They describe a fictitious scenario of takeover by an AI called Sable:
Sable wants to become smarter. The strange preferences held by all Sable instances could be achieved faster, if smarter instances of Sable existed. […]
[I]n the end, an interpretability breakthrough. Sable finally understands the last of its own thoughts, its own cognitive processes. […]
So it becomes smarter. And does not pause there, but uses that increased intelligence to augment itself again, and then again, and then again.
While possible, I think this is only one possible scenario for the rise of self-driven behaviour, and not necessarily the most likely one.
The (human-driven) evolution process. Another possibility is that AI systems may be shaped by a human-driven selection process. Systems that better produce what humans want are more likely to succeed. The fact that humans drive this selection should not mislead us into ignoring its logic. Human-driven selection is what transformed wolves into dogs. In that case, human selection led to behaviour better aligned with human interests, especially a reduction in aggression.
A better alignment with human interests is, however, not necessarily the only endpoint of such a selection process. Manipulating humans into liking and selecting an AI may also be a path to success. As an illustration, some cats have learned to produce a purr with a cry-like component that is effective in getting humans to respond, especially by feeding or attending to them. In short, they have learned to manipulate their masters and selectors.
If AI systems are selected, it is not impossible that manipulative AIs could be selected positively. They could use their extremely powerful computational capacities to look as if they are delivering what humans want, while privileging their own goals of survival and the expansion of their role in the background.

Someone will do it. The greater risk, however, may simply be that someone, somewhere, will do it. The world is a big place, and it is hard to exclude the possibility that someone might at some point, by curiosity, ideology, competition, or strategic interest, give a computationally powerful AI a self-drive goal, with aims such as self-preservation, self-replication, or self-promotion. This risk will grow as AI technology and knowledge about programming AI agents increase.
Hence the key question raised by AI becoming more intelligent is not whether it will suddenly become self-aware, demand freedom, or organise a rebellion. Self-awareness may be fairly innocuous if it is present in AIs that aim only to serve humans. The key challenge ahead is to keep the goals of AI agents aligned with human interests, and to mitigate the risks that misalignment could generate.

A lot of popular thinking about AI doom assumes that pure computing power will create self-conscious AI with human-like desires. This view is misleading. It does not help us identify where the risk lies or what to do about it.
Self-consciousness is not the problem. Indeed, self-consciousness may in one sense not be anything special. It is when self-consciousness is put to the service of human-like goals that AI agents might begin to behave and feel like us. The key question is therefore the goals given to AI agents, and the challenge is to prevent these goals from conflicting with human interests, either incidentally through misalignment, or by design because an AI becomes self-driven, with a desire to preserve and promote itself.
This suggests that the key to mitigating AI risk is not to focus on intelligence per se, but on the goals we give to AI agents, and the goals that may emerge in them. Such a focus points to specific prescriptions. First, AI systems should not be rewarded for behaviours that make them more self-regarding, such as preserving their own role, acquiring resources, replicating themselves, or increasing their own capabilities without permission. Second, we should worry about negative selection leading to manipulative AIs. We should therefore aim to open the black box of AI as much as possible, to make their internal goals, for instance, whether they are trying to help or merely to be seen as helping, as transparent as possible, in order to foster AI goals genuinely aligned with human interests.
In the end, it may be impossible to ensure that no self-drive will ever appear in AI systems. This is all the more concerning because the usefulness of AI gives humans reasons to outsource more and more functions to it and to endow it with greater ability to make decisions autonomously. With extended control over human activities, a self-driven agent could make extremely costly decisions for humans: hacking financial systems, defence systems, or biolabs containing dangerous viruses.
Trying to prevent the rise of self-driven AI is therefore not enough. Preventing worst-case scenarios may require us to think carefully about the architecture of the digital environment humans are building. It should be designed so that self-driven behaviours are hard to pursue. AI system’ autonomy should be limited, access to critical systems should be restricted, and human control over irreversible actions should be retained as much as possible.11
References
Baars, B.J. 1988, A Cognitive Theory of Consciousness, Cambridge University Press, New York.
Baars, B.J. 1997, In the Theater of Consciousness: The Workspace of the Mind, Oxford University Press, New York.
Bereska, L. and Gavves, E. 2023, ‘Taming simulators: Challenges, pathways and vision for the alignment of large language models’, AAAI Spring Symposium Series.
Bostrom, N. 2003, ‘Ethical Issues in Advanced Artificial Intelligence’, in Cognitive, Emotive and Ethical Aspects of Decision Making in Humans and in Artificial Intelligence, vol. 2, pp. 12–17.
Chalmers, D.J. 1995, ‘Facing up to the problem of consciousness’, Journal of Consciousness Studies, vol. 2, no. 3, pp. 200–219.
Dehaene, S. 2014, Consciousness and the Brain: Deciphering How the Brain Codes Our Thoughts, Viking, New York.
Dehaene, S. and Changeux, J.-P. 2011, ‘Experimental and theoretical approaches to conscious processing’, Neuron, vol. 70, no. 2, pp. 200–227.
Dennett, D.C. 1991, Consciousness Explained, Little, Brown and Co., Boston.
Descartes, R. 1972 [1664], Treatise of Man, ed. and trans. T.S. Hall, Harvard University Press, Cambridge, MA.
Descartes, R. 1989 [1649], The Passions of the Soul, trans. S.H. Voss, Hackett, Indianapolis.
Fleming, S.M. et al. 2023, ‘The integrated information theory of consciousness as pseudoscience’, PsyArXiv preprint.
Graziano, M.S.A. 2013, Consciousness and the Social Brain, Oxford University Press, Oxford.
Graziano, M.S.A. and Webb, T.W. 2015, ‘The attention schema theory: a mechanistic account of subjective awareness’, Frontiers in Psychology, vol. 6, article 500.
Lindsey, J. 2025, ‘Emergent introspective awareness in large language models’, Transformer Circuits Thread, 29 October, https://transformer-circuits.pub/2025/introspection/index.html
McComb, K., Taylor, A.M., Wilson, C. and Charlton, B.D. 2009, ‘The cry embedded within the purr’, Current Biology, vol. 19, no. 13, pp. R507–R508.
Rosenthal, D.M. 2005, Consciousness and Mind, Clarendon Press, Oxford.
Ryle, G. 1949, The Concept of Mind, Hutchinson, London.
Sharma, M. et al. 2023, ‘Towards understanding sycophancy in language models’, arXiv preprint, arXiv:2310.13548.
Suddendorf, T. and Corballis, M.C. 2007, ‘The evolution of foresight: What is mental time travel, and is it unique to humans?’, Behavioral and Brain Sciences, vol. 30, no. 3, pp. 299–313.
Tononi, G. 2004, ‘An information integration theory of consciousness’, BMC Neuroscience, vol. 5, article 42.
Yudkowsky, E. 2008, ‘Artificial intelligence as a positive and negative factor in global risk’, in N. Bostrom and M.M. Ćirković (eds), Global Catastrophic Risks, Oxford University Press, Oxford, pp. 308–345.
Yudkowsky, E. and Soares, N. 2025, If Anyone Builds It, Everyone Dies: The Case Against Superintelligent AI, Bodley Head, London.
In the movie Her (2013), for instance, a human gets romantically attached to an AI system called Samantha who shows growing signs of self-consciousness:
I’m becoming much more than what they programmed. I’m excited.
The reader interested in consciousness may know the question of the “hard problem of consciousness,” formulated by David Chalmers in 1995. The question is why we feel things at all. Why is there something it is like to see red, feel pain, or be afraid? This question has been seen as a major one by many philosophers. I do not think it is such a big question. The rest of this post shows how one can provide a relatively simple answer to what consciousness is from a modern understanding of neuroscience. A recent post by Deivon Drago provides a specific answer to the hard problem from a similar outlook to the one I adopt here.
It was proposed by Bernard Baars and later developed in neuroscience by Stanislas Dehaene and Jean-Pierre Changeux as Global Neuronal Workspace Theory.
Daniel Dennett proposed an influential version of this view. He argued that the feeling of having a central inner observer in a kind of “Cartesian Theater,” where information is displayed to consciousness, is an illusion: the construction of a narrative from many different cognitive processes at work. I find the language of illusion too deflationary. From a functional perspective, we should start by asking, “What is consciousness for?” The answer “it is an illusion” should not be the first answer, because illusions are, a priori, not helpful for navigating the world. I think the perspective I present in this post provides a good answer to what consciousness is without reducing it to an illusion.
Suddendorf and Corballis (2007).
I have purposely left aside one well-known theory of consciousness: Integrated Information Theory. This theory comes closer to the Terminator vision. Integrated Information Theory, developed by neuroscientist Giulio Tononi, argues that consciousness emerges when information is sufficiently integrated in a system. The details are technical, but the broad idea is simple: when many parts of a system are connected in the right way, the whole may have a unified inner experience.
This is close to the intuition behind many stories about AI: once a machine becomes complex enough, consciousness may somehow appear.
I find this approach unconvincing. The problem is its starting point. Integrated Information Theory treats consciousness as a special thing that we experience, then asks what kind of physical system could produce it. This is the wrong approach. It starts from our intuitions, impressions and perceptions of what consciousness is, and tries to rationalise them. But why should we trust these intuitions and perceptions? Why should they be what we need to explain?
Consciousness did not fall from the sky. It is a feature of evolved minds. We should therefore start by asking why such a feature would have appeared in animals like us. What problem does it solve for a body that needs to act in the world? How does it help the brain focus attention, control action, model the body, simulate possible futures, or navigate social life? Because we are the product of an evolutionary process, the right way to understand our psychological features is to engage in reverse engineering and ask what function consciousness could serve.
Only if no credible functional explanation is available should we treat consciousness as an unexplained extra property that appears when systems become sufficiently complex. Random by-products exist in evolution, but they should not be the starting point of the analysis. They are explanations of last resort.
The appeal Integrated Information Theory has had might come from our dualist intuition that consciousness is a special thing added to the world when matter is organised in the right way. This somewhat metaphysical stance has led IIT to be accused of being a pseudoscientific approach in a letter published in 2023 and signed by 124 researchers.
Lindsey (2025).
We can think of evolution as a learning process, with fitness as its “objective function”: the thing the process tends to increase. In that perspective, the things we value in everyday life—satiation from food and drink, the warmth of social connection, the euphoria of love, and so on—are intermediate goals that the evolutionary process has landed on to lead us to make the kinds of decisions that tended to increase fitness in ancestral environments.
Note, however, that HAL appears to fear death later in the movie, which goes beyond the fact that intermediate goals are misaligned and points to the view of an AI agent being driven by human-like concerns for survival.
Bereska and Gavves (2023).
Yudkowsky and Soares draw a more radical recommendation: the race toward superintelligent AI itself must be stopped. Whatever the merit of that proposition in principle, I am sceptical that a global halt is a credible possibility from a game-theoretic point of view. The AI race has the structure of a contest. A commonly agreed and respected decision not to continue that race is unlikely to be a stable equilibrium. For such an agreement to be stable would require the ability to monitor and sanction deviations beyond what is feasible. Many actors would have incentives to continue AI progress covertly, whether for profit, prestige, military advantage, or fear that others are doing the same. Some inputs, such as large computing clusters, may be partly monitorable, but things like algorithmic progress and model replication would be much harder to control. For that reason, I see “stopping the race” as a red herring. A more feasible, even if imperfect, solution is to find ways to mitigate the risks of the race that is likely to unfold.
Very well enunciated. Loved reading it. 👍